
Our first project at Metis was assigned on the first day of class, and was due at the end of the week. Fortunately, this exploratory data analysis project was also the only one to be done with a group, and the dataset to be used was a popular one.
Setting the Scene
Our group was to consult for a fictional non-profit organization that is fundraising and raising awareness for a “women in tech” gala in early summer, by stationing teams outside of subway stations to pass out flyers and gather emails. We used the MTA’s turnstile data to determine the most popular stations during which times of the day. The project was great practice for cleaning a large and quirky dataset.
In addition, we cross referenced the stations with the most foot traffic with New York Census data to determine which neighborhoods had 1) a higher average income, as we were soliciting for donors, 2) a higher ratio of females to males, as we were looking for both supporters and participants of women in tech, and 3) a larger proportion of transit takers, as we needed to actually come across these people.
Finally, we also researched which areas of Manhattan contained a higher concentration of tech jobs and companies.

Assumptions and Issues
The New York MTA turnstile data is a very popular teaching data set because it involves a lot of cleaning before being able to read and analyze it. We used pandas to read in the data and for most of the data wrangling.
- The MTA posts one week of data at a time, and we used data from May of last year, as the gala was to be held in early summer.
- The value counts for each group of turnstiles at a station are cumulative, so we had to calculate the net changes for entries and exits (footfalls). Snapshots were taken approximately every 4 hours for most stations, but not all at the same time. Counters were sometimes reset back to 0 or were counting backwards, so we eliminated net readings below 0 and above 100,000 for each 4 hour interval.
- We only included “regular” turnstile readings and removed the rest (<0.5% of the total data points).
- Different stations fall under the same name in the dataset (e.g. 14 ST, 96 ST, etc.), but the stations in real life could be up to 2 miles apart because they were running different lines.
Findings
Weekdays had drastically more volume than weekends, so we narrowed down our dataframe and concentrated our efforts on weekdays only. We found the top 20 stations, then binned the footfalls into 4-hour increments throughout the day and plotted it on a Seaborn heatmap. To no one’s surprise, the morning and evening rush hours were the most popular times of day.
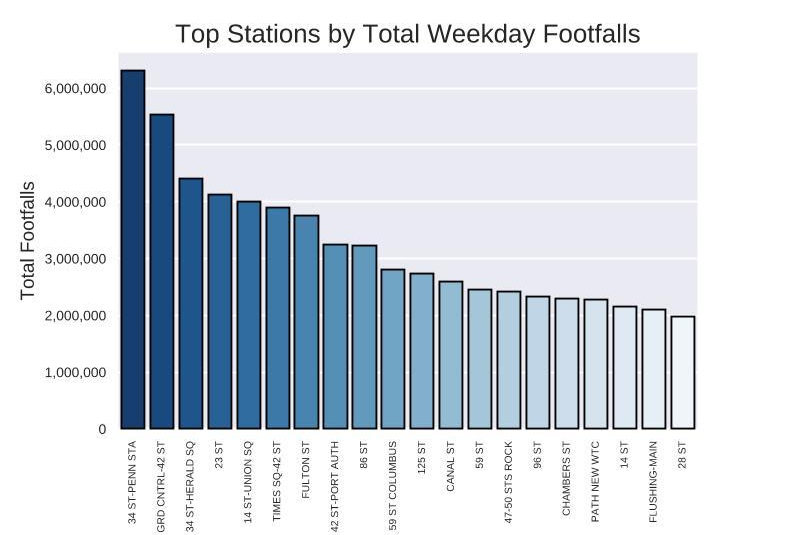
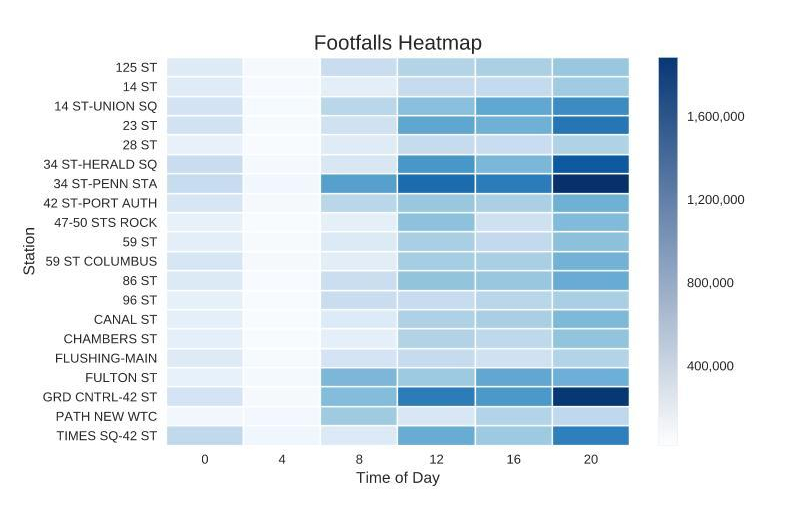
After applying a weighted score that we used to combine the census and tech company data, we came up with a tiered recommendation based on the number of street teams available. For example, if we had only one team available at 20:00, we would dispatch them to Grand Central Station instead of Penn Station to reach the most number of relevant people.

Future Considerations
No one in our group had lived in New York before, so we could have used some more local knowledge into the behavior and profile type of transit takers, as we probably would not want to solicit tourists for a local gala. We were also unaware of the different lines for each station until the day we presented the project.
To apply this into a real business case, I would include more years of data and get a calendar of local tech events and highlight the stations nearby. There’s a lot of other information and data that could be combined with the MTA turnstile data to get a clearer picture of this city’s movements, but this was a great introduction to how to structure a data science project and how to produce a minimum viable product (MVP).
Tools used: Python, Pandas, Jupyter Notebook, Matplotlib, Seaborn
